Internet packet sizes part 2: IPv4 path MTU discovery is dead
▼ Please read yesterday's post Maximum packet sizes on the internet first. There, I looked at the maximum supported packet sizes that are included in the TCP MSS option in HTTP requests to my server. Today I'll look at the values in ICMP(v6) "too big" messages.
(If you don't need the history lesson, skip ahead to "IPv4 measurements".)
The computer making that HTTP request doesn't necessarily know about the MTU sizes supported along the entire path that the data flows over. If the hops in between support larger packets, there is no issue, although it would be more efficient if we could make use of that ability.
The problems start if there's one or more hops along the way that can't support the packet size that the two computers that are communicating want to use. These days, pretty much everything is Ethernet, so a 1500-byte MTU would be expected. (Ironically, most of the technologies that are now replaced by Ethernet, such as IP over ATM and IP over FDDI, support packet sizes much larger than 1500 bytes.)
However, various types of tunnels (including VPNs) as well as PPP over Ethernet may reduce the the MTU for a given hop to less than 1500. The original way that IP(v4) handled this was through fragmentation. So if a host (computer) sends a 1500-byte IPv4 packet, but the next hop is a PPPoE link that can only handle 1492 bytes, the router will break the original packet into two fragments. Almost always the first packet will be a 1492-byte one, and the second packet holds the remaining 8 bytes It has its own copy of the IP header, so its total size is 28 bytes. (It would be much better to make two 760-byte packets...)
Fragmentation creates a whole bunch of problems. First of all, it takes a lot of extra time and processing for the router to fragment packets. Then the receiving host has to spend extra CPU cycles to reassemble the packet. If the communication rate is high enough, a lost fragment can easily lead to the situation where fragments of two different packets are reassembled. Usually, the TCP/UDP checksum will catch this, but that checksum isn't very strong, so one in every 65000 or so instances, it won't catch the problem and the communication will be corrupted. Last but not least, because the TCP/UDP port numbers are only present in the first fragment, NATs and firewalls have a hard time dealing with fragments.
The solution is path MTU discovery (PMTUD), which was specified in 1990. In order to avoid fragmentation in routers, hosts try to figure out the largest packets they can send to another host without fragmentation. They do this by setting the DF (don't fragment) bit in the IPv4 header. With that bit set, routers aren't allowed to fragment the packet. Instead, they send back a "packet too big but fragmentation needed" message. The PMTUD specification updated this message's format to include the supported packet size. This makes PMTUD very easy: simply send packets as large as you like with the DF bit set, and if you get "too big" messages back, lower your packet size to the value in the too big message.
However, this introduced a new problem: if the too big message doesn't make it back, either because the router didn't generate it, it got lost along the way or because it was filtered by a firewall, the host keeps resending large packets that never make it to their destination. To add insult to injury, the initial TCP handshake uses small packets, so that part works, but then the packets that actually contain data never make it to the other side. This is a PMTUD black hole.
PMTUD is optional with IPv4, although it's universally used, even by people who filter the ICMP "too big" messages. With IPv6, if you want to send packets larger than 1280 bytes, PMTUD is mandatory, as routers aren't allowed to fragment IPv6 packets. And unlike with IPv4, PMTUD also works for non-TCP protocols (such as UDP) with IPv6, as the source host's networking stack will fragment non-TCP packets before transmission. Enough background, on to the...
IPv4 measurements
Over the course of more than five days, my server received 52758 IPv4 ICMP messages. Those were:
- 52047 echo request (someone pinging me)
- 1 echo reply (me pinging someone)
- 645 unreachable
- 61 time exceeded in transit (traceroute)
- 3 unknown
In almost a week, I received zero IPv4 "too big" messages.
So it seems in the IPv4 world, path MTU discovery is dead. Turns out that so many people filter ICMP messages, that if you rely on PMTUD for IPv4, there's just too much breakage. So what (home) routers that sit in front of a reduced-MTU link do is "MSS clamping". They rewrite the value in the TCP MSS option to what's supported on the interface they're about to transmit the packet over.
(Please don't read this as "it's ok to filter ICMP "too big" messages. It could easily be that some users still depend on these.)
IPv6 measurements
Over the same five days, my server received 57244 ICMPv6 messages:
- 41471 neighbor solicitations (similar to an IPv4 ARP request)
- 15288 neighbor advertisements (similar to an IPv4 ARP reply)
- 17 echo request (ping)
- 17 echo reply (ping)
- 84 too big
- 366 unknown
The 84 ICMPv6 too big messages came from 9 unique sources, although one of those is a tunnel gateway that returned two different sizes for (presumably) two different tunnels. So that's 10 values, with the following distribution:
- 1280: 3 (30%)
- 1428: 1 (10%)
- 1472: 1 (10%)
- 1480: 5 (50%)
One of those 1480 results is my own connection at home, which uses an IPv6-in-IPv4 tunnel terminated on my home router. So my computers at home don't know the path MTU is 1480 and depend on PMTUD, which seems to work without obvious problems. Maybe two or three times a week I encounter a page that won't load, which may or may not be an IPv6-related issue, which in turn may or may not be a PTMUD issue.
Hopefully, IPv6 won't lose PMTUD to ICMP filtering like IPv4 did. MSS clamping is effective for TCP, but it doesn't work for non-TCP protocols or IPsec-protected communication. It's also a burden on routers.
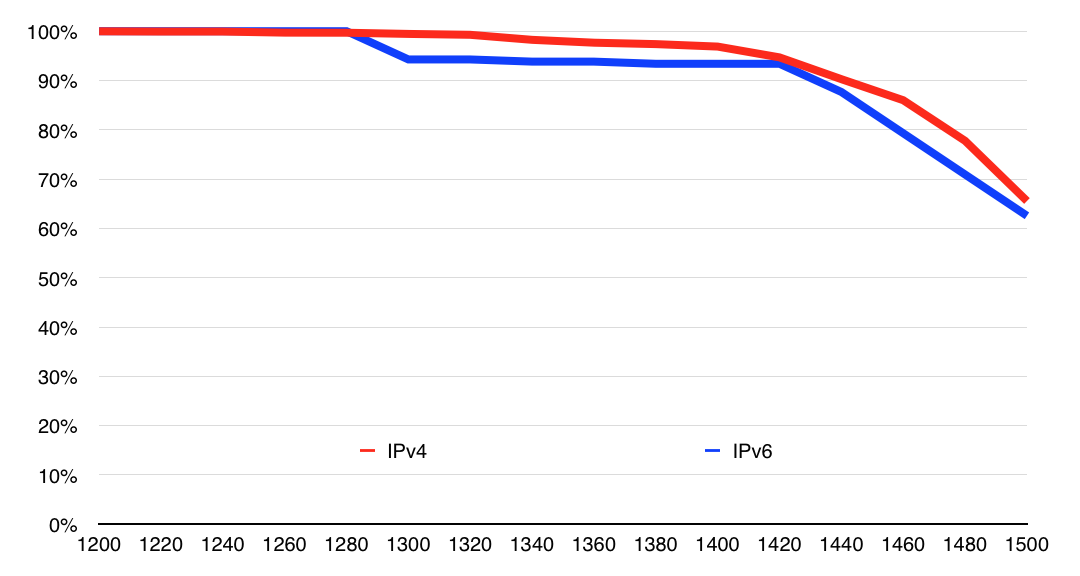
Stéphane Bortzmeyer replied to yesterday's post with a link to this 20-year-old (to the day!) message, which has results for very similar measurements. The results are different in interesting ways, with the real stunner being that in 1994, 94% of all systems could handle 1500 bytes, but in 2014, this is down to 65%.
Permalink - posted 2014-12-18